Quiet inspired by the biometric reading and would like to create my own biometric authentication system. First I gather 10 recordings from 3 ITP friends and myself pronouncing my name "KEZIA", then data augment each of them into 100 recordings per recording. Unfortunately, my computer broke before I could save this project.
So for quick reconstruction, I recorded myself speaking in 4 different style of "KEZIA" that I've heard other people calling my name with such pronunciation. It should be noted that since all of the recordings are mine, they're all in similar pitch. I'm not sure if this is defying from the initial biometric idea, since all the voices belong to me, I just pronounce it differently.
What is biometric really? How does the model differ 1 audio recording from another? Is it all the combination of the way it being pronounced, the pitch, the loudness, the timbre of the sound? Or perhaps there is a weighted / prioritized feature amongst those.
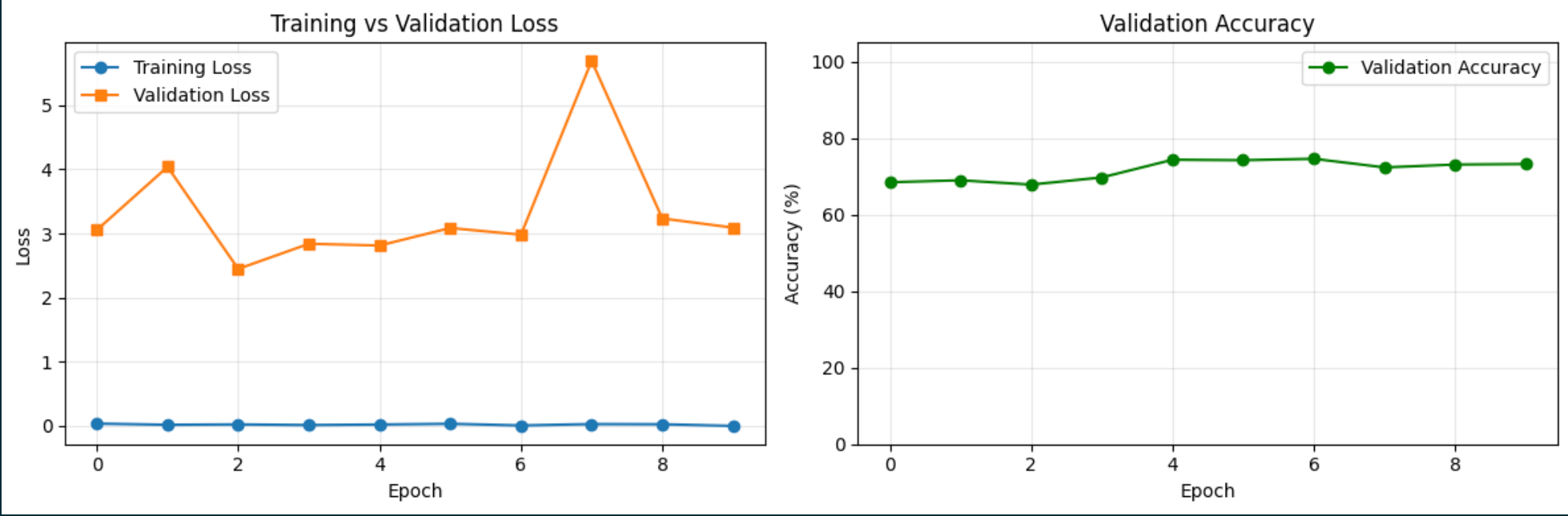
Anyway, the result doesn't look that promising. I remember running the model that was trained on 4 different people before the computer broke and it is definitely not producing accurate result, despite the fact that the validation graph goes down. And now here I present the sad validation graph of the model that I trained on my own voice:
And here's the demo:
Elizabeth Kezia Widjaja © 2026 🙂