Keywords:
- Group Authorization
- Collective biometrics
- multi-party authentication or threshold access control
Context:
This project is situated in a near-future condition in which biometric authentication has become normalized infrastructure. Voice assistants, facial recognition, and fingerprint systems increasingly bind access, ownership, and decision-making authority to individual biological identity.
The work explores an alternative model:
authentication as collective (and even social) presence rather than individual verification.
Partly inspired by Project CyberSyn in Chile -> a distributed decision support system to aid the national economy (economic simulator, check factory performance, operation room, network). The similarity of my idea ends at the distributed part.
But if we imagine this group biometric policy being implemented in a larger scale, it can mean:
- No individual can unlock sensitive data.
- Data belongs to a collective (community, research group, activist cell).
- Access requires quorum voices
This distributes risk of biometric abuse:
- coercion of one person is insufficient
- stolen biometric ≠ system compromise
Real world implementation (so far) (although it is not audio-based):
- nuclear launch authorization
- Multi-Signature Cryptographic Systems
- multi factor authentication
Where is the audio based examples? Where can listening machine step in here?
To be honest…
Collective biometric unlocking is uncommon because:
- Biometrics are probabilistic (false positives/negatives complicate threshold logic).
- Coordination friction reduces usability.
- Cryptographic keys are more reliable than biometrics for threshold systems.
But…
Collective voice authentication becomes relevant when authorization itself is intended to be social rather than individual. The question is less technical feasibility and more whether a system benefits from distributed consent.
Voice has social advantages, can be:
- naturally synchronous/co-presence
- difficult to silently delegate (cannot make u speak unconsciously like how people can push the finger on the scanning device unconsciously)
- embeds presence and participation
- you fully aware that you’re speaking XXX rather than just looking into the camera. Your speech informs the consent that you are currently performing.
So why listening machine?
The machine contains the algorithm to detect the cipher, while both the individual carries 2-part cipher (each carries one). We need the listening machine to transcribe what the individuals are saying, whether it matches the stored cipher, and then unlock the data.
Why do people need to speak here?
Speech becomes a performed consent for data access.
Content:
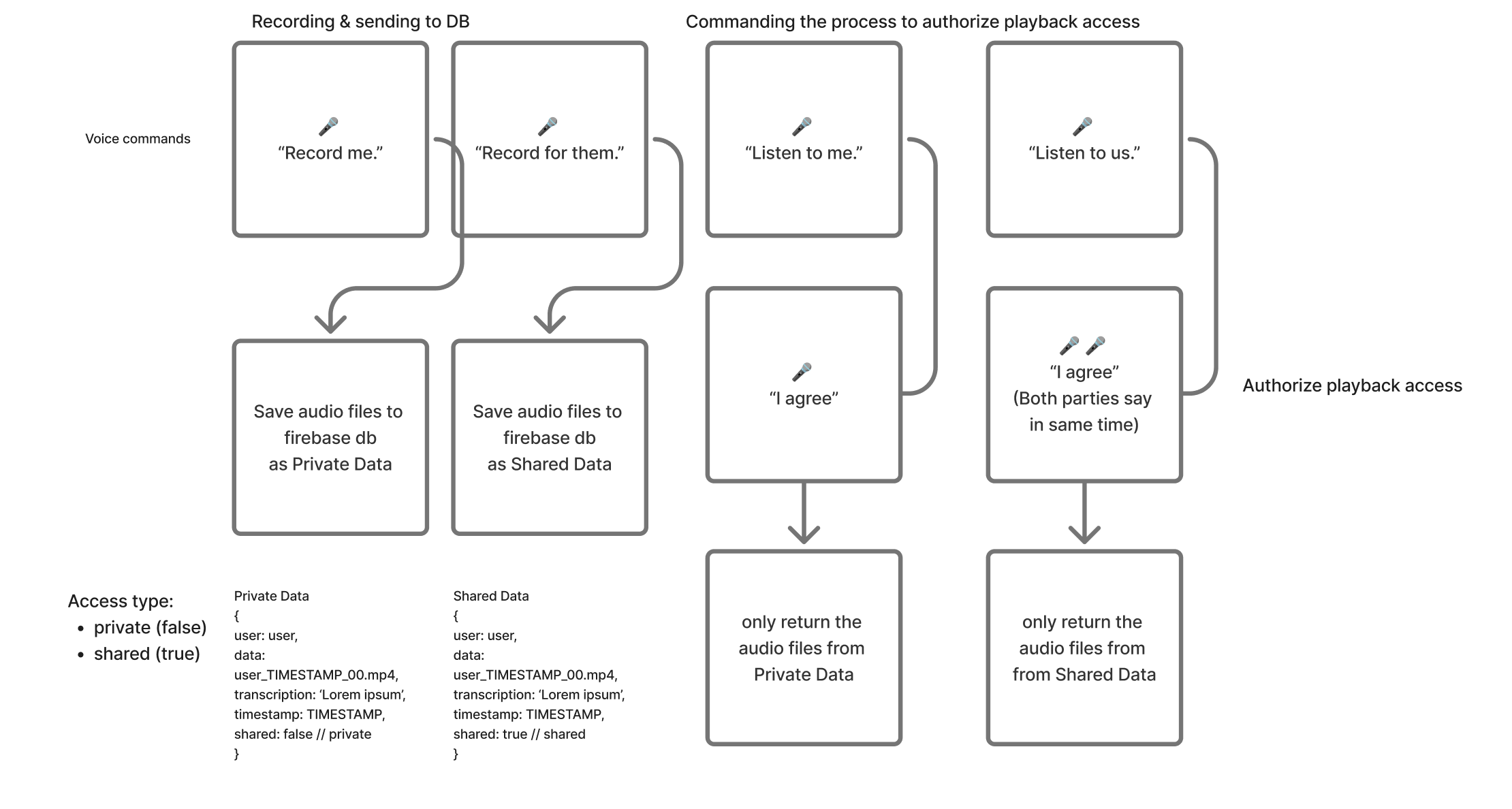
- Multiple voices. Likely for this POC just mine & another person’s. Recording a designated T&C-like command “I agree"
- Person A will unlock Data A. Person B will unlock Data B. If both voices are detected as each individual and are heard within the threshold of the timeframe, then Data C will be unlocked.
- Data C will be a form of shared data (but still not public!) between the two parties, while Data A & Data B is individually private.
- Whatsapp message inspired, but controlled by voice commands
- The Data: voice (with transcription) message
Concept:
- An artistic-slash-POC to demonstrate collective/group voice biometric authentication, mediated by a Chrome tab and/or physical device.
Critical aspect: - Questioning whether identity is attached to just one person or can be multi people
- Can identity belong to multiple bodies instead?
- The term and conditions agreement as the command for the listening machine as a metaphor to
- Who knows… Future systems may intentionally avoid single biometric ownership. Maybe we can speculate about it with this POC.
Technical aspect: - An alternative to diversify risk of putting information under singular identity
- This collective biometric system seeks for agreement to co-exist between multiparties instead of the existence of an individual
Reference:
The biometric idea is provoked from reading “The Native Ear” by Michelle Pfeiffer. Although the project won’t be touching the subject of immigrants, it questions the use of voice-based identification to acquire data access. Similar to the voice as the passport, the voice biometric here becomes a key to unlock some access/privilege.
Issues
Seems very challenging to be able to detect 2 speakers in 1 recording that are speaking synchronously. Proposed solution will be having them speak to their device at the same time. Each person will have independent device. Record the timestamp of the recording and if it is falling in the same threshold, allow it to process the audio. If not, return early.
Question: what is the best way to detect that person A/B/Others is speaking and *also* saying xxx word?
Possibility of training strategy
A.
- Class 1 → You
- Class 2 → Person B
- Class 3 → Anyone else in the world
The difficulty is that “everyone else” is not a real class.
You cannot directly train a model on infinite unknown speakers.
So the correct formulation is verification + rejection, not ordinary 3-class classification.
The model may only work on the trained random people data set -> open-set recognition failure
B.
Class 1: You
Class 2: Person B
Use embeddings
Audio → Speaker Encoder (speechbrain on py) → Embedding (vector)
Then use the embedding distance score to determine whether it is closely resembling your voice, or B, or some weirdo
Do I need Negative Samples?
- silence
- random speech
- wrong phrases
- other people saying “I agree”
Without negatives, the model may trigger constantly?
Method
- Dataset collection: 10 recordings of “I consent”
- Model training (CNN +embeddings)
- Real-time detection flow
- Decision logic (if only A is valid, then gibe data A to A, if only B, give data B to B, if both is valid, then send data C to A & B.
User Flow
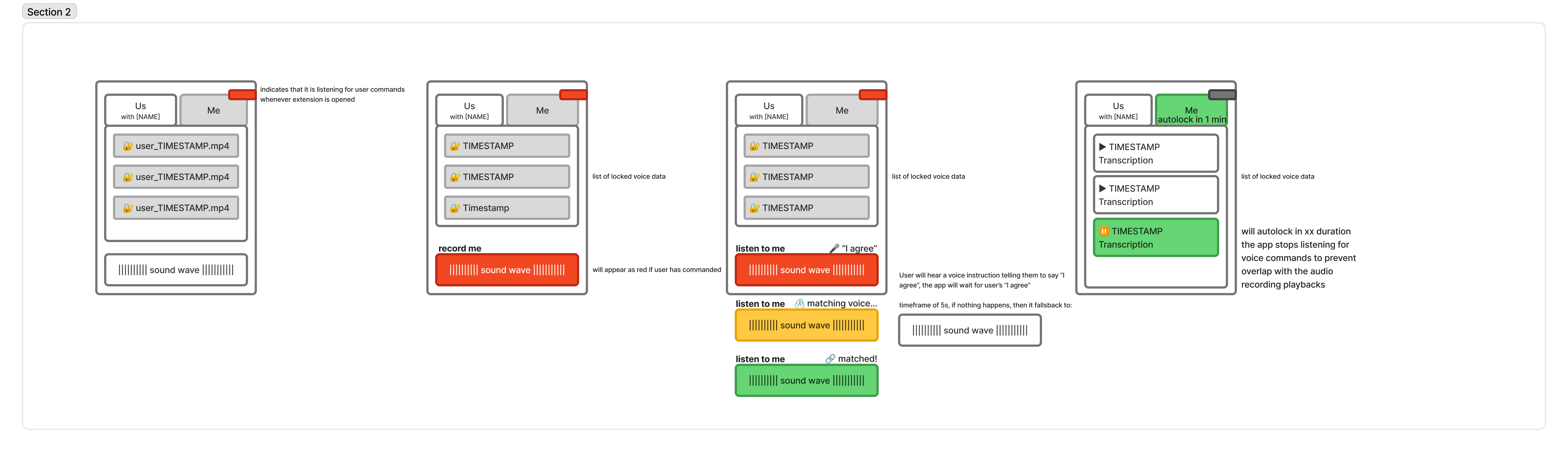
UI Overview
Elizabeth Kezia Widjaja © 2026 🙂